The C Book. Сама не читала, по слухам старенькая, но хорошая.

Modular Arithmetic Challenge
15 часов назад
C++0x теперь надо называть C++09. Комитет по стандартизации решил, что новый стандарт C++ будет в 2009. Отступать им уже некуда, C++010 уже не получается из C++0x заменой икса на цифру. Поэтому в 2007 году будут рассматриваться ранее присланные предложения, дорабатываться старые. Новые приниматься не будут. В 2008 финальный документ будет отдан на стандартизацию в ISO. А в 2009 у нас будет новый стандарт.
Чем больше я смотрю на предложения по стандарту и работу над ними, тем больше они мне нравится. Еще по книге D&E видно как Страуструп тщательно подходит к разработке языка. Чтобы ни в коем случае не сломать ничей код. Чтобы обеспечить обратную совместимость, старается не вводить новые ключевые слова. Каждое новое предложение по языку тщательно обдумывается и рассматривается со всех сторон. А не сломает ли его претворение в жизнь что-либо старое? А не выйдет ли боком в дальнейшем? Можно ли как-то добиться того же самого эффекта без реализации этого предложения? Насколько сложно это будет реализовать разработчикам компиляторов? После прочтения этой книги мое уважение к Страуструпу удвоилось.
Поскольку цель введения нового стандарта - это предоставление программистам более удобного и современного инструмента для работы, а не что-нибудь вроде Порабощения Вселенной, то результат обещает быть хорошим. Многие вещи просто напрашивались. Как например использование ключевого слова volatile для обеспечения доступа к переменной из разных потоков. (Сейчас это не так!) Кстати, когда я писала про C++0x, в комментариях было высказано предположение, что вот, да пока его примут, да пока компиляторы напишут... В VC++2005 volatile уже так и работает. Много внимания уделяется многопоточному программированию. Сейчас для стандартизации рассматривается библиотека: Multithreading API for C++0X - A Layered Approach. Планируется введение ключевого слова atomic для атомарных операций.
После прочтения у меня не было ощущения "ну вот, придется все заново учить". Будет принято много новых полезных вещей, которые облегчат мне работу, в дополнение к уже имеющимся. Будут устранены мелкие шероховатости. Я подумываю разобраться поподробнее с новыми волшебными фичами C++. Чтобы к моменту выхода нового стандарта быть уже во всеоружии. Ну и конечно написать о них несколько постов. Но все это будет чуть позже, когда предложения по стандарту примут более законченный вид.
Ссылки по теме:
State of C++ Evolution
Wikipedia: C++0x
C++09: Proposals by Statuses
Bjarne Stroustrup's homepage
Морис Эшер (Maurits Cornelis Escher 1898 – 1972) был знаменит своей способностью рисовать картины, которые приводят в восторг математиков. При этом сам он никакого специального математического образования не получил. Отсутствие математического образования не мешало ему рисовать платоновы тела, листы Мёбиуса, неевклидовы пространства. Мало того, что это все математически корректно, это все еще и очень красиво.
 Змеи |  Рыба и чешуя |  Передел круга III |
| In mathematical quarters, the regular division of the plane has been considered theoretically . . . Does this mean that it is an exclusively mathematical question? In my opinion, it does not. [Mathematicians] have opened the gate leading to an extensive domain, but they have not entered this domain themselves. By their very nature thay are more interested in the way in which the gate is opened than in the garden lying behind it. | В математических кругах регулярное разбиение плоскости рассмативается теоретически... Означает ли это, что это исключительно математический вопрос? Я считаю, что нет. [Математики] открыли дверь в огромный мир, но они сами в этот мир не вошли. По своей природе им больше интересно как открывается эта дверь, а не сад, лежащий за ней. |


 Спирали |  Рисующие руки |
Visual C++ Team Blog - по названию понятно кто пишет и о чем. Унылый-унылый такой.
Как значится в моем профайле, я сейчас занимаюсь разработкой игры под рабочим названием Winding Trail (русское название мы еще не придумали).
С радостью сообщаю, что мы выпустили демку, которая доступна для просмотра всем желающим. Хех, на самом деле мы ее выпустили в конце декабря и те, кто читает блог Winding Trail Project, ее уже видели. Но до сих пор мы ее особенно не афишировали, потому что опасались за то, что у нас получилось нечто, что лучше не показывать.
Так что афиширование начинается только сейчас, когда мы уже получили некоторое количество отзывов. Есть жалобы на баги, есть глюки на сравнительно экзотических видеокартах, есть только один удручающий репорт от человека с вполне обычной конфигурацией, у которого демка отказывается работать наотрез. Но в целом для демки все нормально. Так что приглашаю к просмотру: Winding Trail Demo
 |  |
Листала C++ Faq Lite, очень хороший там раздел про освобождение памяти. Хотя, там вообще все разделы хорошие. Пара моментов оттуда.
Выражение delete p и оператор delete это разные вещи. Выражение вида delete p; делает нечто вроде
if (p != NULL) {
p->~Fred();
operator delete(p);
}
if (p != NULL)
delete p;
Fred* p = new Fred[100];
...
delete[] p;
Листая GCC wiki наткнулась на блоги разработчиков GCC. Ни один из приведенных блогов меня особенно не заинтересовал, но вдруг кому пригодится.
Блоггер переводит своих пользователей на новую версию постепенно. В дашборде должна была появиться волшебная кнопочка "переключиться на новую версию". У меня она появилась вчера.
Мелкие глюки, возникшие в результате преключения я подчистила довольно быстро. Но были и более крупные неприятности, например сглючила синдикация в ЖЖ - оно решило, что это новый блог с новыми постами и теперь у людей из ЖЖ в френдлентах оказалась половина моего блога. Боюсь, что могли возникнуть проблемы и еще у кого-то. Всем пострадавшим приношу свои извинения.
Блоггер перешел к динамическому формированию страниц, что правильно. Работать стало гораздо удобнее. С остальными фичами я пока разбираюсь.
Также я сняла Google AdSense. Все с ними хорошо, кроме релевантности. Когда я ставила себе Google AdSense, то думала, что у меня на блоге будет крутиться реклама различных ресурсов, посвященных программированию, каких-нибудь программок из серии "в помощь программисту". На самом деле чего тут у меня только не было. И реклама сект каких-то, языковых курсов. В ноябре мне явилась просто апокалиптическая картина.
В последнее время здесь появился Forex каким-то боком. Вообще в Google AdSense можно зафильтровать ресурсы, которые не нравятся тебе по каким-то причинам и их реклама больше на сайте не появится. Я, честно говоря, упарилась с фильтрованием. Я бы лучше наоборот: выбрала из списка сотню ресурсов, которые я хочу видеть на моем блоге. Короче говоря, Google AdSense здесь больше не живет. Я хотела было поэкспериментировать с Яндекс.Директ, но там есть обязательное условие, по которому я не прохожу - платный хостинг. Поэтому рекламы не будет (пока по крайней мере). На радость многим, я думаю :-)
На прошедших затяжных праздниках я заинтересовалась поиском по глубокому вебу, начиталась статей всяких разных, спешу поделиться.
Термин Глубокий веб (deep web, иногда употребляются invisible web, hidden web) обычно относится к веб-страницам, которые по тем или иным причинам не индексируются поисковыми роботами. Соответственно, если вы ищете что-либо своим любимым поисковиком, вы не сможете с его помощью найти страницы, которые этот поисковик не проиндексировал.
Это особенно печально, потому что очень распространено ассоциирование любимого поисковика со всем вебом, да что там с вебом - со всем Интернетом. Причем я вот не знаю откуда берется такое заблуждение. Знаю людей, для которых Интернет и Рамблер это вообще одно и то же. Рамблер ничего путного по запросу выдать не смог, значит в Интернете этого нет.
Почему страница может быть не проиндексирована? Чтобы это выяснить, надо понять как работают поисковые роботы. Стандартное очень упрощенное описание поискового паука: берет страницу, индексирует, ползет по ссылкам с нее, индексирует их, ползет по ссылкам с этих страниц и так далее. Слабость такого паука например в том, что он никогда не найдет страницу, на которую нет ссылки (то есть имеет место зависимость от связности веб-страниц). Такой простой паук найдет только статические страницы. Но обойдет стороной страницы, создаваемые только по запросу пользователя. В качестве примера сайтов с такими страницами в Рунете мне пришли в голову только банки данных вакансий и резюме. В англоязычных источниках упоминаются всякие разные базы данных: базы данных патенов, базы данных научных статей и т.п. Также не будет проиндексирован контент, закрытый паролем, страницы, на которые нет ссылок. Обычно не индексируются страницы, запрещенные к индексированию файлом robots.txt. Некоторое время останутся непроиндексированными новые страницы. Могут остаться непроиндексированными файлы в нетекстовом формате (.pdf, .doc), сайты на флэше.
Первые статьи по глубокому вебу, которые я нашла относятся к 1999 - 2001 годам. Статья, которую больше всего рекомендуют: The Deep Web: Surfacing Hidden Value.
Красивая картинка оттуда: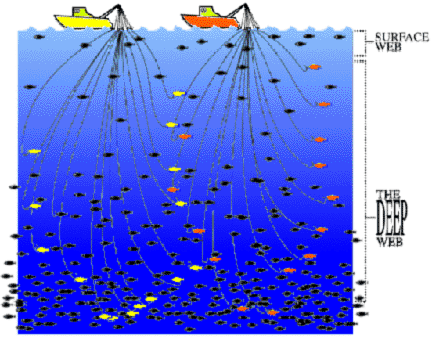
Статья была написана в 2001 году и примечательна тем, что там приводятся оценки размера и качества глубокого веба. И эти оценки цитируются до сих пор. Оценки получены методами близкими к гаданию на кофейной гуще, имхо. Вообще довольно сложно посчитать то, чего не видно. Плюс ситуация меняется чуть ли не каждый день.
Но ничего другого все равно нет, так что вот они. Глубокий веб по объемам превышает обычный в 400-500 раз. Поисковые роботы индексируют примерно 16 процентов от всего веб-контента. Глубокий веб более качественный (в среднем в три раза качественнее обычного). И еще глубокий веб растет быстрее всего.
С тех далеких времен ситуация изменилась. Глубокий веб пытаются индексировать по мере сил и возможностей. Наиболее показательны здесь старания Google - индексирование pdf, doc, содержимого библиотек, чего угодно. Они сравнительно недавно запатентовали способ поиска в глубоком вебе: Searching through content which is accessible through web-based forms.
В целом борьба за доступность информации в глубоком вебе ведется с трех сторон.
1. Со стороны пользователей. Пользователям советуют искать тщательнее.
Здесь народ пытается найти способы добраться как-нибудь до глубокого веба. Например, попробовать использовать запрос вместе со словом database. В статье How to Search the Invisible Web приводится пример: пользователь пытается найти статистику по катастрофам с самолетами в Аргентине. Если задать запрос в Yahoo вроде "plane crash Argentina", то в ответ вы получите кучу газетных заголовков. А если запросить "aviation database", то найдете NTSB Aviation Accident Database, например. Как раз то, что нужно.
Еще советуют использовать несколько более узкоспециальный поиск: Google Book Search, Google Scholar, Google Code Search
2. Со стороны владельцев страниц. Владельцам страниц дают советы как обеспечить доступ поисковых роботов к содержимому страницы.
Вот есть у меня динамически формируемый из базы данных контент, который не индексируется поисковыми машинами. Что делать?
Если база данных небольшая, то вывалить все содержимое на одну статичную страницу. Снабдив ссылкой с интерфейсом к базе данных конечно же. Если информации слишком много, то поместить на отдельную страницу хотя бы какую-то избранную.
pdf - файлы, презентации и т.п., перевести в текстовый формат. (Google по pdf'ам прекрасно себе ищет, про остальных не знаю). А аудио и видео выкладывать с описаниями.
Убрать логины и прочие ограничения.
Избавиться от флеша.
3. Со стороны поисковиков.
Вот это самый правильный путь на мой взгляд - попытаться поисковым роботом добраться до глубокого веба. Ибо, как известно, вкалывать должны роботы, а не человек.
Самая часто упоминаемая статья по этому поводу "Indexing the invisible web: a survey", авторы Yanbo Ru и Ellis Horowitz. Я уже было отчаялась найти ее в онлайне, но потом вышла на выложенную в сети через поиск по блогам. Статья посвящена работе с информацией, расположенной в открытых бесплатных базах данных, к которым пользователь может обращаться через веб-формы (это все те же базы данных научных статей и т.п., упомянутые мною выше). То есть, похоже, тому же, чему посвящен Гугловский патент, о котором я говорила. Статья эта исследует варианты решения проблемы и ссылается на большую кучу работ.
Кратенько о чем там. Задачи перед пауком ставлятся следующие: распознать страничку, являющуюся интерфейсом к базе данных и классифицировать ее.
Распознать такую страницу можно по тегу form. Но тег form используется не только для для интерфейсов к базам данных. Это может быть логин куда-либо, это может быть веб форма отправки писем. Как понять что встретилось пауку? В статье обсуждается два подхода. Первый: анализировать саму форму. Ну логично, если в форме есть input с пометкой "пароль", то тут скорее всего предлагается пользователю куда-то залогиниться. Второй путь - послать что либо в форму и посмотреть что получится.
Далее следует классификация страницы, нужно понять это база данных чего. Тут тоже изучаются два пути. Первый - классификация с помощью анализа сайта, на котором веб форма находится. Второй - опять туда чего-нибудь наприсылать и проанализировать ответы.
Нашли, классифицировали. Что дальше - надо этот сайт проиндексировать. Пытаемся задавать запросы, индексируем то, что получили на выходе. Есть еще такой вариант - не индексировать сайт, а хранить где-либо информацию об этом найденном сайте и перенаправлять туда запросы пользователя по мере надобности.
На каждом из вышеперечисленных этапов встречаются свои проблемы и тонкости, в статье об этом всем хорошо написано.
Еще одна интересная статья на эту тему Index Structures for Querying the Deep Web
Ссылки по теме
Research Beyond Google: 119 Authoritative, Invisible, and Comprehensive Resources
The Ultimate Guide to the Invisible Web
CompletePlanet.com - поиск по различным базам данных. Не впечатлил он меня как-то.
Google Unveils More of the Invisible Web - заметка 2001 года о том, что Google начал индексировать нетекстовый контент.
Д.А. Шестаков, Н.С. Воронцова. Структура русскоязычной части глубинного Веба. [.pdf]
В комментариях koudesnik упомянул еще статью по теме Structured Databases on the Web: Observations and Implications
На сервисах, которые разнимаются раздачей файлов, часто можно встретить предупреждения вроде: "Качать в несколько потоков с одного IP нельзя, download менеджерами тоже пользоваться нельзя, а то руки оторвем". Что-нибудь в таком духе. Это не очень эффективно, поскольку человека можно поймать только постфактум, да и не очень вежливо. Если люди хотят пользоваться download менеджерами (они, кстати, всё норовят прикинуться браузерами), то пускай пользуются, но под контролем. И два поста Контролируемое скачивание и Контролируемое скачивание 2 посвящены реализации именно такой раздачи файлов, причем при условии довольно жесткого ограничения по памяти. Ценность этих постов еще и в том, что там подробно расписывается ход мыслей программиста, все испробованные подходы и возникавшие проблемы.
Видеолекции Structure and Interpretation of Computer Programs, которые читают сотрудники MIT'а работникам Хьюлетт-Паккарда.
Там же есть книга к этому курсу, на английском: Structure and Interpretation of Computer Programs. В русском переводе эта книга называется "Структура и интерпретация компьютерных программ".
Нашла по ссылке с CyberZX.
Рекламный ролик о том, что бывает с сисадминами, когда падает сеть.
Нашла по ссылке с dirty.ru.
Я решила продолжить традицию, начатую в прошлом году и перечислить лучшие посты за прошедший год. "Лучшесть" я оцениваю по посещаемости. Надо сказать, популярность некоторых постов остается для меня загадкой. Итак, все как в прошлый раз.
По основной теме блога: язык программирования C++
Три поста по этой теме были популярны. Это: Ключевое слово typename, Ключевое слово volatile, Триграфы и альтернативные символы.
Я думала, что Хорошие книги по C++ тоже вызовут большой интерес. Но так не случилось. Интерес такой, средненький. При этом видела жалобы на то, что я не выкладываю эти книги и не привожу ссылки на варез сайты, а вместо этого даю ссылки на сайты, где можно эти книги купить. Мне все же не хочется превращать свой блог в каталог варезов. И, честно говоря, найти эти книги при желании где-нибудь в P2P сетях или на тех же варез сайтах большого труда не составит. При поиске "что почитать" для меня всегда основной проблемой было перечитывание огромной массы откровенно мусорных книг, это сжирает ужасно много времени. Сейчас я прежде чем читать что либо как минимум смотрю отзывы на Озоне и Амазоне. Очень помогает.
По программированию в целом
Пост о CAPTCHA, опубликованный еще год назад до сих пор уверенно держится в топах. Иногда этот пост из топов исчезал, но потом все равно возвращался.
Я надеялась, что серия постов об отрисовке графов будет востребована, так и случилось. Но что меня удивило, что самой популярной частью оказалась довольно специфичная Теория отрисовки графов.
Ссылки на Несколько редких книг по программированию также занимают лидирующие позиции.
До сих пор уверенно посещаются Хорошие книги по организации кода, О найме разработчиков, Несколько ссылок по физике автомобиля.
Развлекаловка
Переводы слухов о Windows Vista, а именно Обсуждение Windows Vista на блоге Mini-Microsoft и Частичный перевод обсуждения Microsoft's Not So Happy Family на slashdot.org сослужили мне плохую службу. В комментариях к ним все еще пытается разгореться священная война, я это ненавижу. Хотя польза от чтения этих обсуждений есть несомненная - посмотреть какие проблемы возникают при разработке софта такого масштаба с обратной совместимостью и сделать выводы для себя. При этом не надо забывать, что это очень однобокий взгляд.
Кроме этого никого не оставила равнодушной непростая жизнь тараканов.
На всякий случай хочу напомнить, что для этого блога есть Syndicated Account в livejournal. Я даже не знаю кто его сделал и кому говорить спасибо...
На текущий год у меня опять огромное количество планов. Новая версия Блоггера выходит из состояния беты. С бетой я не экспериментировала, но сейчас воспользуюсь самыми интересными новыми фичами. Особенно меня заинтересовали категории.
Планы у меня не только по оформлению блога, но и определенные посты я уже запланировала. Да, я с удовольствием выслушаю предложения, критику, ваше мнение об этом блоге, все что поможет сделать этот блог интереснее. Пишите мылом, мылом общаться удобнее.
Оставайтесь с нами!
 Atom feed
Atom feed